
Cutting 95th percentile latency from 3 minutes to 500ms
or: Every Email, Everywhere, All At Once

Imagine a haystack with 60 billion pieces of hay and you need to find the strands that are related. In our case, the haystack is digital and contains the metadata for 60 billion emails which we manage securely but also need to make performant. For a while, we had a few API endpoints where the latency spiked, causing some requests to timeout after 3 minutes:
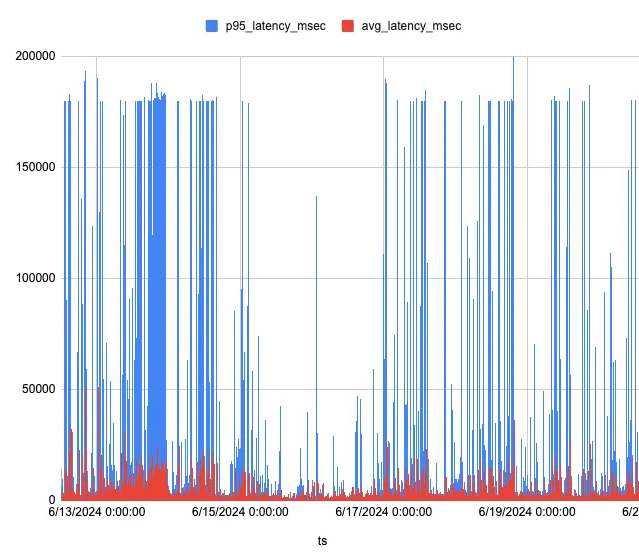
The average latency was a lot less but still spiked into the tens of seconds. After doing numerous optimizations and discovering a nice algorithm to avoid expensive read-time queries, the same API endpoints were vastly improved:
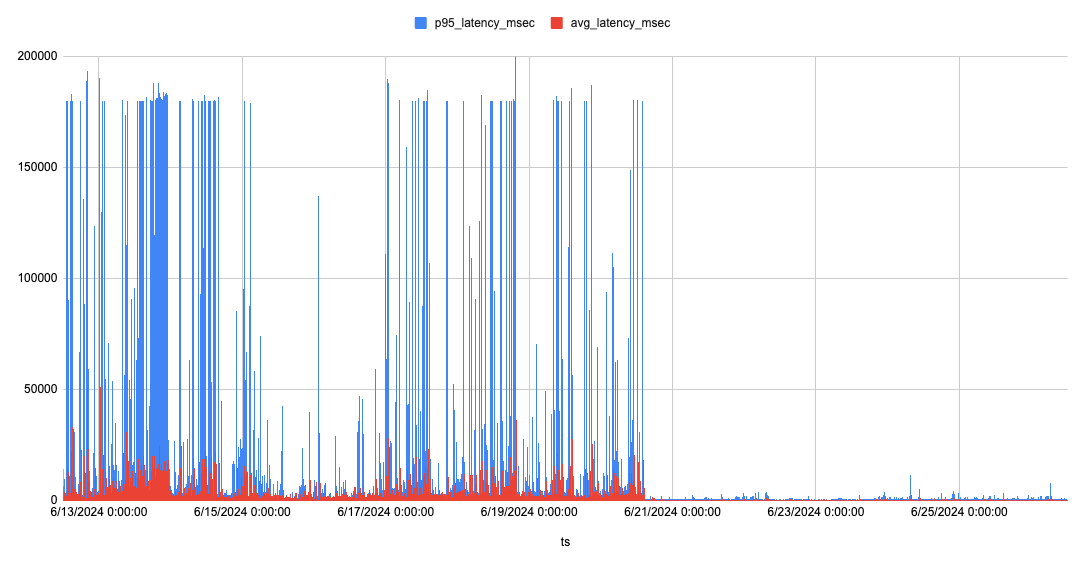
The graph almost looks like things stopped working halfway through the X axis, but zooming in on the data:
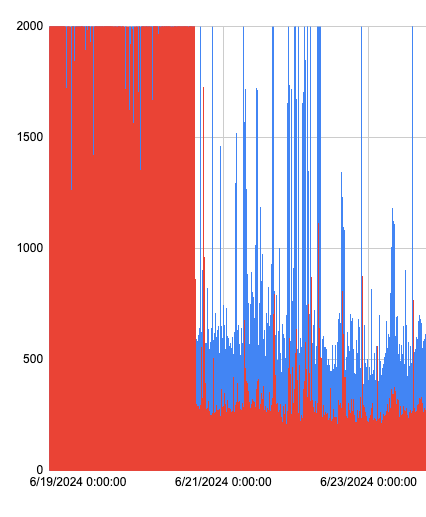
You can see that p95 latency is around the 500ms mark, and average latency about half that. While there are still occasional spikes, they are on the order of seconds, not minutes and return the expected data rather than timing out.
In this post I’ll dive into the problem, the old way of doing things, various infrastructure changes, and how the “threadweaver” algorithm works in detail.
Quick background
Streak’s CRM keeps track of boxes in a pipeline. A box is something like a sales deal or a project. Users can keep track of emails inside these boxes — we call that a “boxed thread” or “boxing an email”. Boxed email threads allow users to share certain emails with all users on their team. It looks like this:
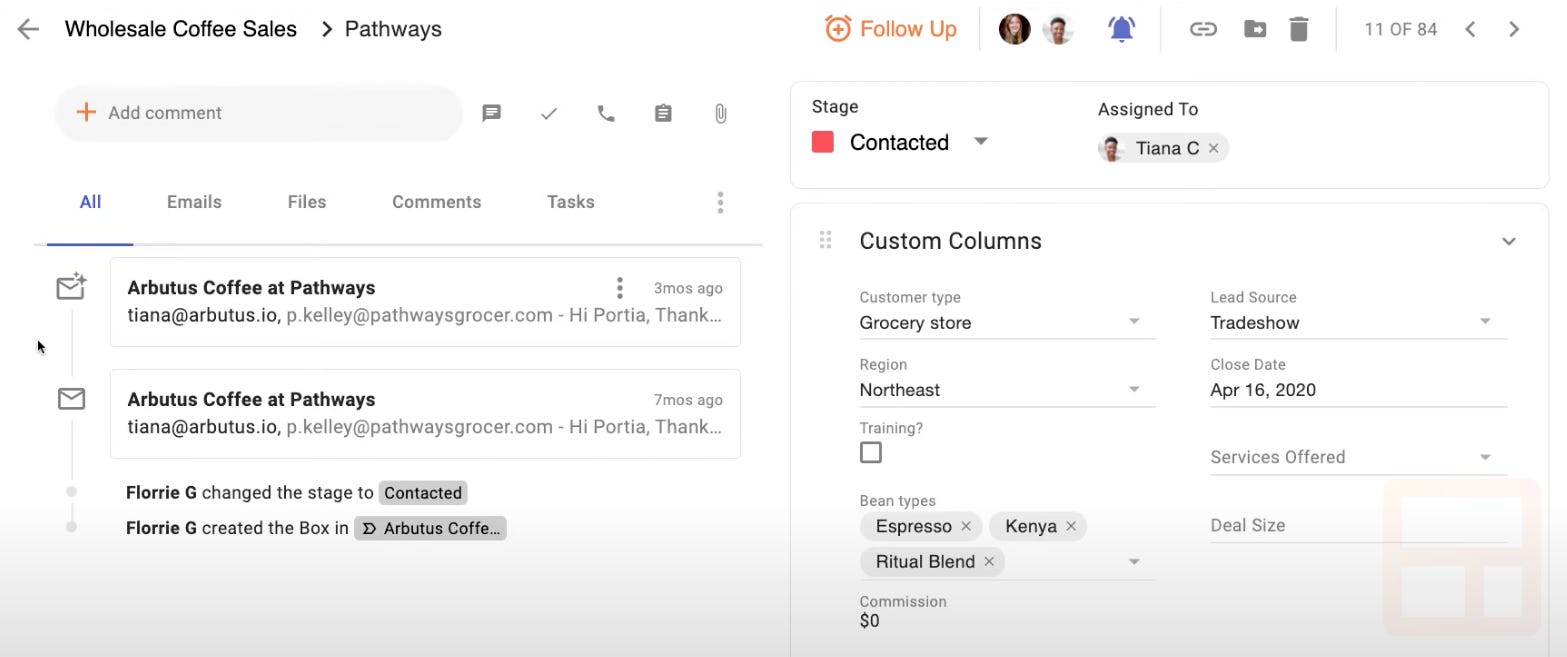
The timeline on the left shows changes to the box including two email threads consisting of an example conversation from our own demo account.
We also support “autoboxing” — in the above example, you can specify that you want Streak to include all emails from the customer’s domain in the box. When enabled, any email sent to or from the customer from any user on your team (subject to each user’s sharing permission) will also be included in the box, automatically.
Unifying with TiDB and JGraph
Let’s say an email thread has 2 messages sent to 10 members of your team. These messages get delivered into everyone’s inboxes:
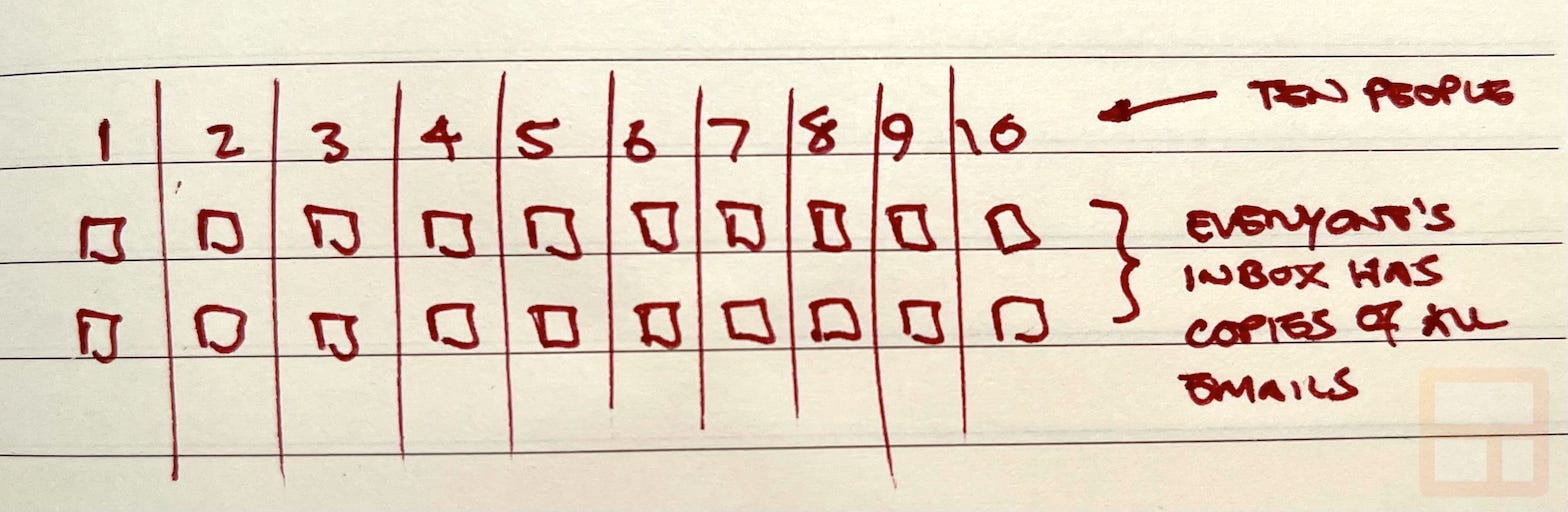
When you’re viewing the box timeline, you just want to see the one email thread, not the 10 copies from each person’s inbox.
So we unify all these individual threads together and only show the unique messages across all members of your team who have shared their emails. Since each email has a Message-ID header uniquely1 identifying it, we can deduplicate the emails regardless of whose inbox they are in.
This was done via a breadth first search using a simple SQL query for the set of users identified by gid (their Google-assigned ID) on the team:
SELECT DISTINCT m2.gid, m2.thread_id FROM messages m1
JOIN messages m2 USING (md5_rfc_message_id)
WHERE (m1.gid, m1.thread_id) IN (:initialSet) AND m2.gid IN (:gidList)The query runs on our TiDB cluster and the data is all nicely indexed so, for most Streak users, this was quite fast. When this query returns threads that weren’t in the initial set, we iterate on those until we get no new threads.
You can try it here. The query starts out with the initial set consisting of gid 1 and thread 1, and running it also finds gid 2 and thread 2. Plugging (2, 2) back into the query then also finds gid 3 and thread 3. Obviously a greatly simplified example, but it demonstrates how the query searches based on matching IDs.
The results are fed into JGraph where we construct a graph representation of all the emails we found and the relationships between them all. This is also where we filtered messages by the user’s custom permissions.
Must be dynamic
One of the reasons we used the above SQL query is that when we unify, the result needs to be dynamic. The unification should reflect changes in their team membership without having to perform lengthy recalculations to reunify the emails. Here’s a simple example where this comes into play:
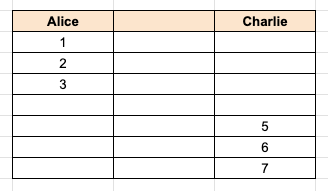
In the image above, Alice has a thread of emails with message ids of 1, 2, 3 and Charlie has a different thread of emails with message ids 5, 6, 7. Because none match we can’t unify them into a single thread. However, let’s see what happens when Bob joins the team:
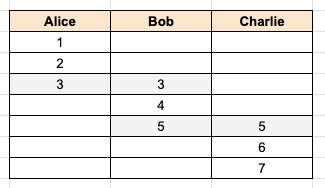
In the image above, Bob has a thread where message id 3 matches an email that Alice has. Similarly, message id 5 matches an email that Charlie has. These previously separate threads can now be unified together into a common thread.
You can try it here. Note that once we insert Bob’s message metadata, we can now connect Alice to Charlie when searching.
Gmail quirks
Gmail has a few interesting quirks that makes the volume of emails increase substantially in a few cases:
messages with the same subject sent within a few days of each other get threaded together, even if there is no relationship between the emails within the thread. We’ve seen this a lot ourselves for automated emails and it’s great for cutting down the number of threads in a person’s inbox.
when a thread has 100 messages, Gmail automatically creates a new thread. For long-running discussions, this ends up creating a bunch of new threads. We informally refer to this as the “multi-centi-thread problem” since each person receiving the emails (could potentially be everyone in the company) will have numerous 100 email threads all tied together.
Performance impact
Small teams saw results very quickly when they went to view a shared email thread. We could quickly identify and unify all threads across their team. But when there were a large number of emails across large teams, the Gmail quirks started causing huge performance issues as shown earlier:
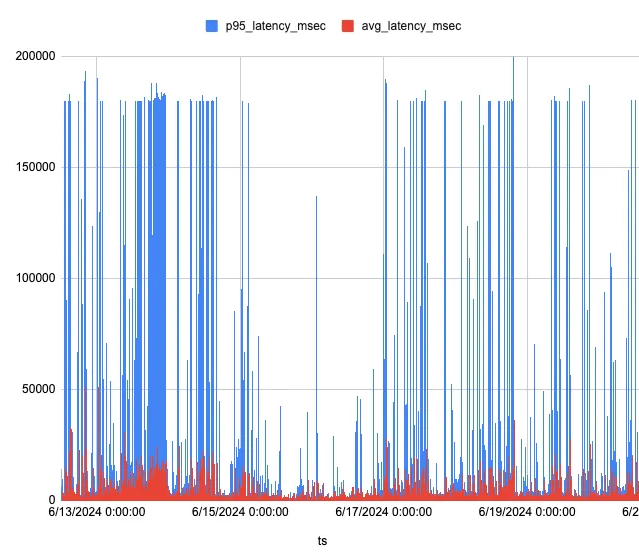
Why is there a flat line at around the 180 second mark? That’s the limit we imposed on the length of a database connection, after which the database server gives up and returns an error.
Additionally, for large volumes of email when the database did return results, on occasion putting that data into JGraph could result in an Out of Memory error.
Practically speaking, for larger teams with a huge volume of emails they would click into a box that had a number of autoboxed threads, go and grab a coffee while they waited for the email data to load, then come back just to see that it returned nothing because the database timed out. Not a great experience!
Results were slightly incorrect
We also took a number of shortcuts in our implementation. In particular, keeping track of stats for these boxed threads could occasionally be inaccurate. By stats I mean things like the timestamp of the last sent or received email. Users use this to create views on their data like “show me all boxes where the last email was more than 3 days ago” or “show me boxes with a reply in the last week”.
Whenever we process a new email for a user, we see if that thread is part of an existing boxed thread. Doing this with full unification using the breadth-first database query was a non-starter due to the potential for heavy load. So we cheated: when processing emails, we ignored processing the email thread unless it was for the one user who boxed the thread.
Let’s say Alice, Bob, and Charlie are all participating on one email thread that was boxed by Charlie. Alice sends a reply to everyone, so there’s now an email in Alice’s sent folder plus emails in Bob and Charlie’s inbox, all with the same Message-Id. When we process Alice’s email, she didn’t box the thread so we ignore it. When we process Bob’s email, he didn’t box the thread either so we ignore that too. Finally we process Charlie’s email and since he was the one who boxed the thread, we update the stats and the last email timestamp accurately reflects the latest email:
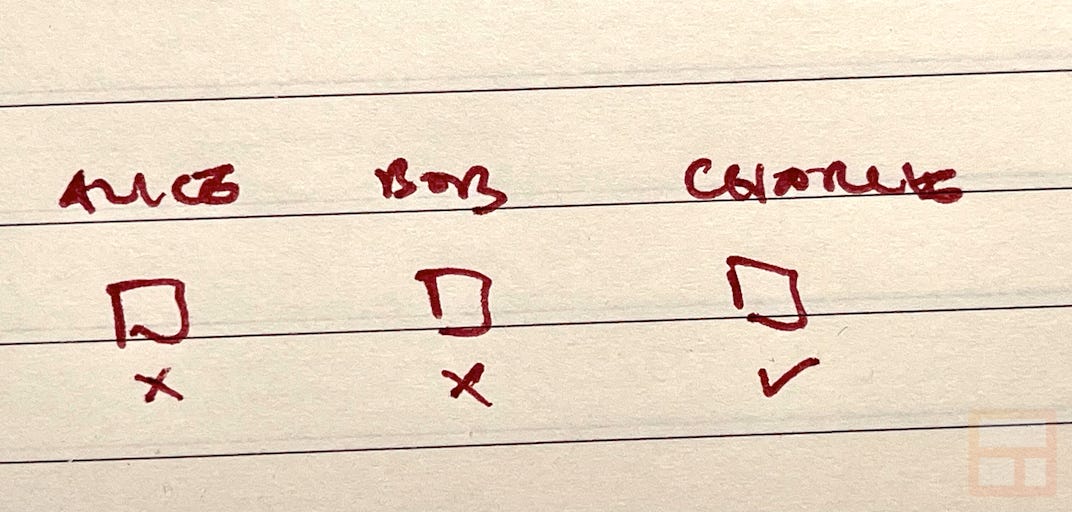
This works for almost all emails, but where it goes wrong is if the person who boxed the thread no longer participates in the emails. Since we are ignoring everyone who didn’t box the thread, the stats never update and this impacted users’ workflows:

Because Charlie was removed as a recipient, and he was the one who boxed the thread, we never updated the stats since the remaining emails we process didn’t correspond with Charlie’s boxed thread and were ignored.
Finding a better algorithm
When you distill all this down from gids, thread ids, and message ids, there are a few simple theorems we can derive:
since we are unifying entire threads, all messages in a single thread are part of the same unified thread
when two messages in two different threads have the same Message-ID, they are part of the same unified thread
So there are really only two inputs we need to concern ourselves with: the thread id and the message id. If we can turn these into a unified thread id and know which individual user threads make up that unified thread, then it becomes a trivial lookup.
We can represent this as the following relationships, where “ut” is a unified thread:
Each threadId and messageId maps to a single unified thread, but a unified thread maps to the set of threadIds that reference it. Let’s model this using a simple scenario where rfc2 means the Message-ID value:
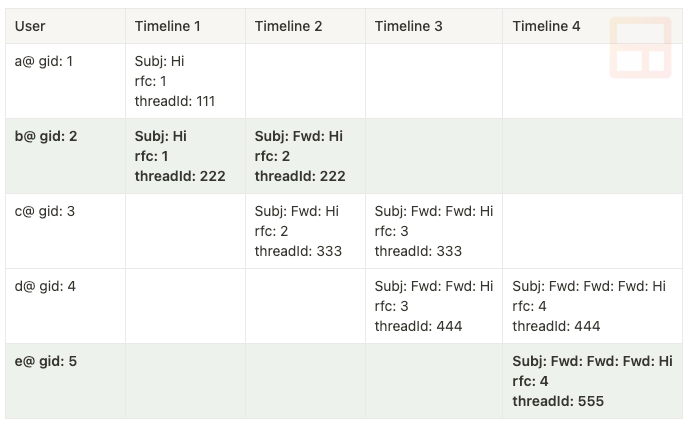
This scenario shows that user A sends a message to B, who then forwards it to C, who then forwards it to D, who then forwards it to E. If we process this in timeline order, one message at a time, we have:
Timeline 1
Does thread “111” map to a unified thread? ❌
Does rfc “1” map to a unified thread? ❌
Assign each to a new unified thread value “ut_a”, and map “ut_a” to the set of{“111”}Does thread “222” map to a unified thread? ❌
Does rfc “1” map to a unified thread? ✅ = “ut_a”
Assign each to the existing unified thread value “ut_a” and add “222” to the “ut_a” set, which now contains{“111”, “222”}
Timeline 2
Does thread “222” map to a unified thread? ✅ = “ut_a”
Does rfc “2” map to a unified thread? ❌
Assign rfc “2” to the existing unified thread value “ut_a”Does thread “333” map to a unified thread? ❌
Does rfc “2” map to a unified thread? ✅ = “ut_a”
Assign thread “333” to the existing unified thread value “ut_a” and add “333” to the “ut_a” set, which now contains{“111”, “222”, “333”}
Timeline 3
Does thread “333” map to a unified thread? ✅ = “ut_a”
Does rfc “3” map to a unified thread? ❌
Assign rfc “3” to the existing unified thread value “ut_a”Does thread “444” map to a unified thread? ❌
Does rfc “3” map to a unified thread? ✅ = “ut_a”
Assign thread “444” to the existing unified thread value “ut_a” and add “444” to the “ut_a” set, which now contains{“111”, “222”, “333”, “444”}
Timeline 4
Does thread “444” map to a unified thread? ✅ = “ut_a”
Does rfc “4” map to a unified thread? ❌
Assign rfc “4” to the existing unified thread value “ut_a”Does thread “555” map to a unified thread? ❌
Does rfc “4” map to a unified thread? ✅ = “ut_a”
Assign thread “555” to the existing unified thread value “ut_a” and add “555” to the “ut_a” set, which now contains{“111”, “222”, “333”, “444”, “555”}
Let’s compare this to how things would’ve worked with the breadth-first SQL query. We would start with thread “111” and find thread “222”. We repeat with thread “222” and find “333”, and so on until we eventually find “555” and a subsequent query doesn’t return any new threads.
But once we’ve written the data in the new format, let’s consider how we lookup the information. We start with thread “111” and lookup the corresponding unified thread, finding “ut_a”. We then lookup “ut_a” and find the set {“111”, “222”, “333”, “444”, “555”}. And that’s it. We’ve turned a recursive breadth-first SQL query into two trivial lookups.
Handling all cases
Remember the earlier example when we processed Alice’s email and Charlie’s email and each thread is distinct, but once Bob joins the team his emails unify the two?
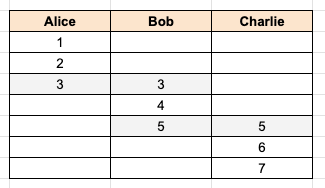
If we processed this using the above timeline example, Alice’s emails would be “ut_a” and Charlie’s emails would be “ut_b” since they have no emails in common. But when Bob joins, we now have an exception: message 3 in Bob’s thread maps to “ut_a” and message 5 in Bob’s thread maps to “ut_b”. How do we handle this?
It’s simple: we store unified thread merges as well. This introduces a new relationship:
When the unified thread for a user’s email thread and the unified thread for one of the messageIds in that thread are different, we record a merge with the unordered pair of unified threads being merged. In the Alice, Bob, and Charlie example that would result in merges containing { (“ut_a”, “ut_b”) }.
This adds one more step to finding all threads given a starting thread:
lookup starting threadId to find unified thread
lookup any merges for the unified thread — if any, recurse finding more merges
from the set of all unified threads identified, lookup the threadIds
While step 2 is recursive, in practice merging threads happens rarely and it’s even rarer that there are multiple merges. To put this in numbers, the storage needed to represent the mapping of threadId → ut, messageId → ut, and ut → {threadId} takes up 9.6 TB. The storage needed to represent all unified thread merges is only 1.4 GB, almost 4 orders of magnitude less data.
Implementing the data storage layer
One requirement for making this algorithm work is that when looking up and storing data, we need strong consistency guarantees. My first thought was to use Redis given that it’s single threaded and implementing this using Lua scripting provides for atomic changes. And, on a sufficiently large system, Redis can support 100K+ queries per second which is within our target of needing to process peak rates of 30K/second. And should we need more capacity, Dragonfly claims an order of magnitude improvement over that.
However, what makes Redis fast is that the entire dataset is loaded in memory, and some back of the envelope math3 showed that the storage requirements would range from an estimate of 9.2 TB typical to over 37 TB in the worst case scenario, and would be impractical to make this work.
Scylla
The next contender was Scylla, a NoSQL system touted as being an improvement over Cassandra. While its storage model is eventually consistent, it also offers lightweight transactions (LWT) which provide for the strong consistency we require.
Here’s what the schema looked like:
-- 1:1 mapping of (gid, thread_id) -> unified thread id
create table if not exists gid_thread_to_ut (
gid ascii,
thread_id ascii,
ut_id ascii, -- some "$gid:$thread_id"
primary key ((gid, thread_id)) -- composite partition key with both gid and thread_id
);
-- reverse lookup of (gid, thread_id) by ut_id
create index if not exists on gid_thread_to_ut (ut_id);
-- 1:1 mapping of rfc message id -> unified thread id
create table if not exists rfc_to_ut (
md5_rfc_message_id ascii,
ut_id ascii, -- some "$gid:$thread_id"
primary key (md5_rfc_message_id)
);
-- reverse lookup of rfc message id by ut_id
create index if not exists on rfc_to_ut (ut_id);
-- n:n mapping, merging source unified thread -> target
create table if not exists ut_merge (
source_ut_id ascii, -- source unified thread merged from
target_ut_id ascii, -- target unified thread merged to
primary key (source_ut_id, target_ut_id)
);
-- reverse lookup of source unified thread by target unified thread
create index if not exists on ut_merge (target_ut_id);The data insertion from Kotlin was super simple:
fun setUTForGidThread(gid: String, threadId: String, defaultUT: String): String {
val query =
SimpleStatement.builder("INSERT INTO gid_thread_to_ut (gid, thread_id, ut_id) VALUES (?, ?, ?) IF NOT EXISTS")
.addPositionalValues(gid, threadId, defaultUT)
.build()
val resultSet = scyllaSession.execute(query)
val row = resultSet.one()
val result =
if (row!!.getBoolean("[applied]")) {
defaultUT
} else {
row.getString("ut_id")!!
}
return result
}The nice thing about Scylla’s LWT inserts is that the “if not exists” will insert the value if and only if a value doesn’t already exist and, in any case, the result of the operation either indicates that the insert was applied, in which case we know that our defaultUT value was inserted, or it returns the existing record in which case we fetch the ut_id value.
Similar for messageId:
fun setUTForMessageId(rfcMessageId: String, defaultUT: String): String {
val md5RfcMessageId = Utils.md5Hash(rfcMessageId)
val query =
SimpleStatement.builder("INSERT INTO rfc_to_ut (md5_rfc_message_id, ut_id) VALUES (?, ?) IF NOT EXISTS")
.addPositionalValues(md5RfcMessageId, defaultUT)
.build()
val resultSet = scyllaSession.execute(query)
val row = resultSet.one()
val result =
if (row!!.getBoolean("[applied]")) {
defaultUT
} else {
row.getString("ut_id")!!
}
return result
}And finally to record a merge:
fun setUTMerge(sourceUT: String, targetUT: String) {
val querySource =
SimpleStatement.builder("INSERT INTO ut_merge (source_ut_id, target_ut_id) VALUES (?, ?) IF NOT EXISTS")
.addPositionalValues(sourceUT, targetUT)
.build()
scyllaSession.execute(querySource)
}Whenever we process an email for a user, we know the user’s gid as well as the threadId. From this, we assume that if a unified thread doesn’t already exist, we’ll use the current thread, which we construct using a string template:
val defaultUT = "$gid:$threadId"So the core algorithm, which I dubbed “threadweaver”, is super simple:
val existingGidThreadUt = getUnifiedThreadForGidThreadId(gid, threadId)
when (existingGidThreadUt) {
null -> {
// thread isn't yet associated with a unified thread
val defaultUT = "$gid:$threadId"
val utFromMessageId = setUTForMessageId(rfcMessageId, defaultUT)
val utFromGidThread = setUTForGidThread(gid, thread, utFromMessageId)
if (utFromGidThread != utFromMessageId) {
setUTMerge(utFromGidThread, utFromMessageId)
}
}
else -> {
// thread already associated with a unified thread
val utFromMessageId = setUTForMessageId(rfcMessageId, existingGidThreadUt)
if (existingGidThreadUt != utFromMessageId) {
setUTMerge(existingGidThreadUt, utFromMessageId)
}
}
}This is trivial to perform on every incoming email we process. We either assign a unified thread, or retrieve the one that already exists for both threadId and messageId. If the two differ, record a merge.
This worked great and comprehensive tests showed that it was functioning correctly, but in practice we ran into a lot of problems with Scylla operationally. Since the only way to guarantee strong consistency is the use of LWT, this made maintenance problematic. While we never modified any data once inserted, part of maintaining a Scylla cluster involves compaction and repair. However, our exclusive use of LWT to the tune of thousands of writes per second appeared to hinder any attempts to perform maintenance. Compaction and repairs never appeared to complete successfully. What should have been simple and routine turned out to be impossible. There’s a comment4 on Hacker News which, unfortunately, echoes my experience.
Given these operational issues, we couldn’t trust our data to Scylla. A shame as the simplicity of “insert … if not exists” made for incredibly easy to understand writes that matched the algorithm beautifully.
Bigtable
We had used Google’s Bigtable extensively in the past. We moved off of it as the workload was more suited to a relational database, but when used for its strengths, it performed exceptionally well. So much so that it earned an unofficial nickname of “Honey Badger” because, like that famous YouTube video5, it handled data effortlessly. Need to fetch thousands of rows? “Honey badger don’t care!” How about millions of rows? “Honey badger don’t care!” Do your rows have thousands of columns? You guessed it: “Honey badger don’t care!” Bigtable’s throughput is insanely fast.
Key to making this work is figuring out how to take advantage of strong consistency. Fortunately, by default a single Bigtable cluster provides strong consistency6 on single row operations which is sufficient. To implement the equivalent of “insert … if not exists” for Bigtable, we can take advantage of conditional writes (or “mutations” in Bigtable’s parlance).
Here’s what the Kotlin code looks like:
val filter =
FILTERS.chain()
.filter(FILTERS.family().exactMatch("gt"))
.filter(FILTERS.qualifier().regex(".+"))
.filter(FILTERS.value().regex(".+"))
// only perform the mutation if the filter doesn't match
// (ie: no matching qualifiers/values)
val mutation = Mutation.create()
.setCell("gt", defaultUT, timestamp, "_")
val conditionalMutation = ConditionalRowMutation
.create("gid-thread-to-ut", rowKey)
.condition(filter)
.otherwise(mutation)
client.checkAndMutateRow(conditionalMutation)I’ll translate what this is doing:
a conditional mutation evaluates the filter provided by
.conditionwhich, if true, runs the mutation provided by.then(not used here) or, if false, runs the mutation provided by.otherwisethe filter used by the condition checks to see if the “gt” column family (a distinct group of columns) contains a qualifier (column name) that contains at least one character having a value that contains at least one character.
the
.otherwisemutation operates on the table “gt-thread-to-ut” for the providedrowKey, setting the cell value to the provideddefaultUTvalue.
The result is that nothing happens if there’s any value already, since an existing value means that this thread is already mapped to a unified thread and, once mapped, we never change it. But if there’s no value, then the mutation executes and we’ve atomically set the mapping from that thread to the unified thread. Because single row operations have strong consistency, there’s no possibility of a race condition here.
The same type of operations are performed for conditionally setting the messageId to unified thread mapping as well as any unified thread merges.
The one difference from Scylla is that this operation doesn’t return whether the mutation took place or if there was already an existing value. So we simply query for the rowKey again to find the unified thread, whether it was the one we just inserted (mutated) or whether it was already there. But those are implementation details; the core threadweaver algorithm remains the same:
val existingGidThreadUt = getUnifiedThreadForGidThreadId(gid, threadId)
when (existingGidThreadUt) {
null -> {
// thread isn't yet associated with a unified thread
val defaultUT = "$gid:$threadId"
val utFromMessageId = setUTForMessageId(rfcMessageId, defaultUT)
val utFromGidThread = setUTForGidThread(gid, thread, utFromMessageId)
if (utFromGidThread != utFromMessageId) {
setUTMerge(utFromGidThread, utFromMessageId)
}
}
else -> {
// thread already associated with a unified thread
val utFromMessageId = setUTForMessageId(rfcMessageId, existingGidThreadUt)
if (existingGidThreadUt != utFromMessageId) {
setUTMerge(existingGidThreadUt, utFromMessageId)
}
}
}Performance
The honey badger of databases doesn’t disappoint. We routinely read anywhere from 50,000 rows per second to almost 250,000 rows per second representing roughly 64 MB/s to 256 MB/s of data transmitted.
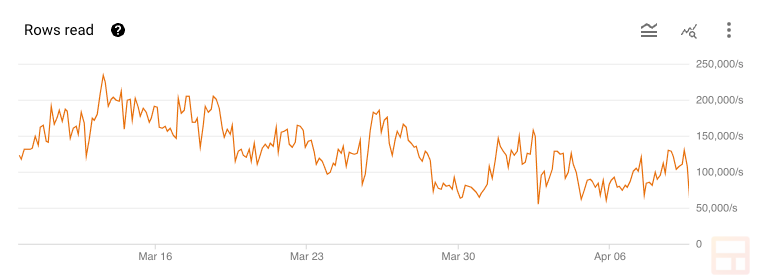
Similarly, Bigtable easily handles writes:
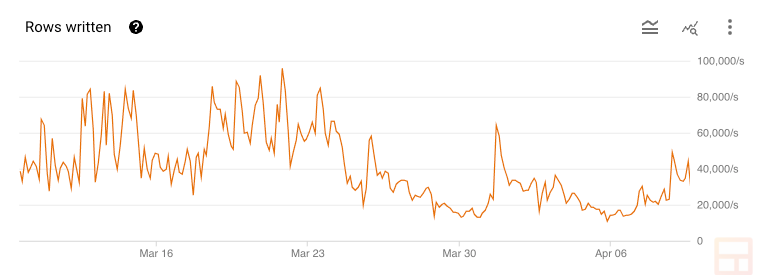
Bigtable also simplifies management. While Scylla would’ve required continuous maintenance with compacting and repairing data plus working around things like VM outages, Bigtable is a managed service. We set the backup schedule, specify how much storage we want per node, set the target CPU% to trigger autoscaling, and Google handles everything. It’s a completely hands-off experience.
Every email, everywhere, all at once
Astute readers may have noticed that this unification algorithm doesn’t have any concept of what team the email we are processing is for. The only inputs under consideration are what thread a message is in and its Message-ID header value. It will happily unify threads for anyone who uses Streak if they were sent the same email having the same Message-ID header value. The result is that every email we process is unified across Streak’s entire userbase. And the simple write-time algorithm has constant O(1) performance.
We restrict emails by team trivially by filtering the results by the list of gid values for our team members. We resolve a starting thread to a set of one or more unified threads, each of which is a self-contained row. It’s then a simple matter to filter the cells7 in the row to those that match our list of gid values.
Once retrieved, we then need to apply individual user permissions based on what their sharing settings are. To do this, we no longer use JGraph as that was overkill, but rather apply the permissions directly on top of the efficiently retrieved data.
User reactions
This log scale graph shows overall performance when fetching the timeline for a box along with all unified threads, showing the same performance improvement as the graphs at the top of the post. The very right side of the graph is from when the change was rolled out to all users:
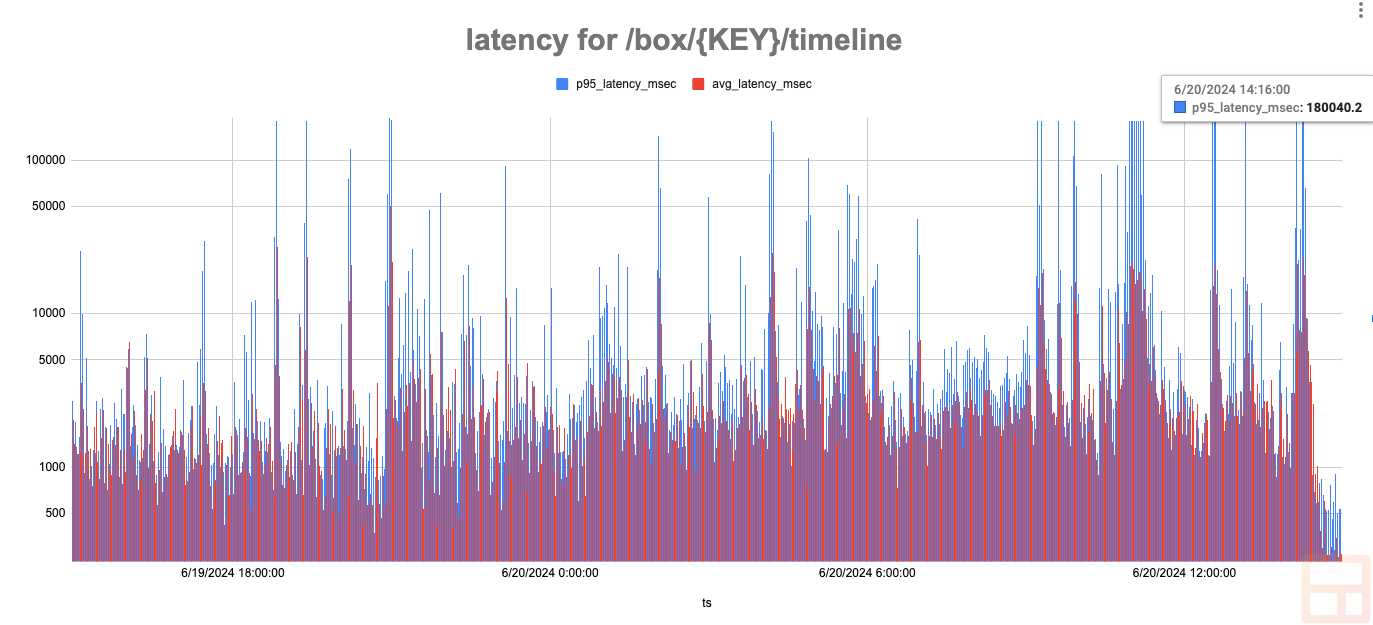
As mentioned at the beginning, this went from “I’m gonna grab a coffee” levels of performance to “I blinked and my data loaded”. Some happy expletives were shared. In addition to instant timeline retrieval, multiple other areas of Streak saw performance gains:
when viewing 50 or 100 threads in your Gmail inbox, identifying which of those are associated with boxed threads is much, much faster
processing autoboxed emails is not only faster but also fully correct, even for the edge cases where the user who boxed a thread no longer participates
quicker retrieval of email threads/envelopes your team has shared with you
Infrastructure changes
Because of the performance gains from the threadweaver algorithm, we no longer needed as many VMs for our TiDB cluster, so we scaled that down as both our storage requirements and query volume dropped dramatically. Additionally, our API servers were no longer tied up waiting for the results of unification, so we ended up needing fewer pods for our API deployment in Kubernetes8. In fact, we used to maintain a separate “threads” API deployment because of the slow performance so that a backlog of thread-related requests wouldn’t impact our regular API traffic. But with threadweaver, performance is little different from any other endpoint, so those API endpoints are now handled by our main deployment.
Engineering at Streak
We work on many interesting challenges affecting billions of requests daily involving many terabytes of data. For more information, visit https://www.streak.com/careers
In practice, Message-ID values aren’t always unique. There are exceptions from systems that aren’t RFC compliant where every email the system generates has some fixed Message-ID header, and even some systems which don’t generate a Message-ID header at all. Exceptions aside, the header value should look like <someuniqueid@domain>. You can read more about recommendations here.
We interchangeably refer to the Message-ID header value as “rfc” since this is from RFC 822: https://www.rfc-editor.org/rfc/rfc822.html#section-4.6.1 and Gmail also has its own internal “messageId” value, which is unused for the purpose of unification.
Based on the Redis docs on memory footprint: https://redis.io/docs/get-started/faq/
I mentioned earlier how some Message-ID values aren’t unique and get reused for every email. We handle this by limiting the number of user threads fetched for a given unified thread. If it’s more than 10,000 then we simply ignore it as those emails are likely to be spam.
These autoscale using a Horizontal Pod Autoscaler. See Implementing blue/green deployments using Kubernetes and Envoy for more info.