
Preventing Flash of Incomplete Markdown when streaming AI responses

You’ve heard of Flash of Unstyled Content (FOUC) before, where you see unstyled HTML appear, then the CSS loads and the browser suddenly updates to display the correct style.
A similar problem exists when streaming responses generated by AI that I call “Flash of Incomplete Markdown” (FOIM). I’ve reproduced this within OpenAI’s playground by throttling my connection speed to dialup internet speeds:
While this is greatly exaggerated due to the slow speed, you can see the incomplete markdown appear in chunks. This occurs because OpenAI’s streaming API returns an event stream where it builds up a response message. These chunks are provided by what are called output text deltas:
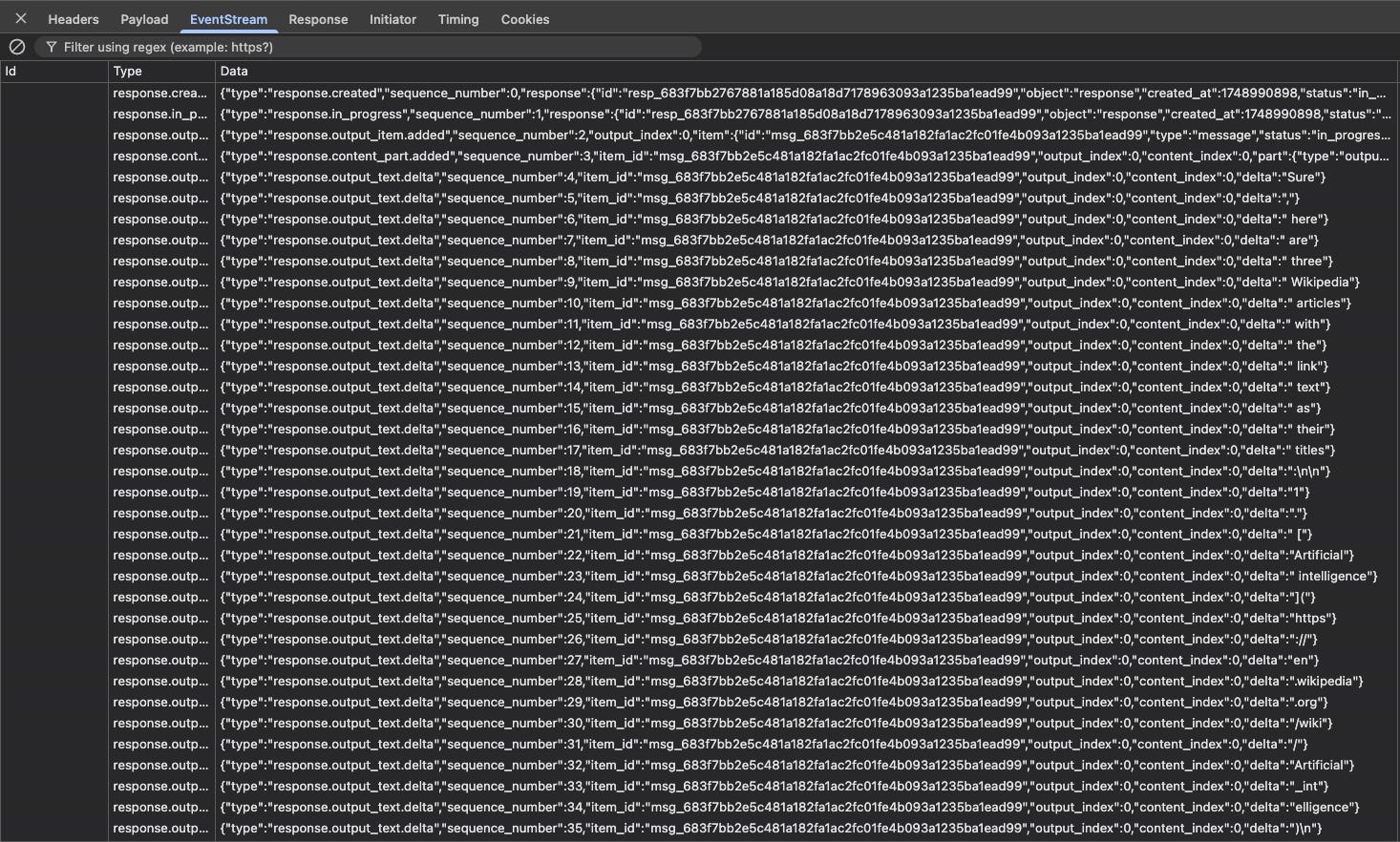
You can read more about output text deltas in their API docs.
I’ve seen this same behavior occur in a number of commercially launched products, so this isn’t some obscure effect. We experienced this in our product as well. One of the AI features Streak offers is the ability to ask a question about one of your deals, where the answer may be in any related email threads, various comments, meeting notes, and so on.
You could ask “When did the customer sign the contract?” and getting back an answer of “Last Thursday” is useful, but even more useful is providing a link to the email thread from Thursday where they sent an email saying “Signed contract attached”. The Streak user can click on that and be confident that the answer is correct. You can see that here as I was implementing the functionality in my dev environment:
What should have been output as trivial [source] links ended up rendering the incomplete markdown using a lengthy link format of https://streak.com/a/boxes/{KEY}/itemtype/{KEY} and only when the browser received the closing ) of the markdown link did the content collapse to show just [source].
Hallucinations
Additionally, when we launched this internally to Streak employees someone reported that one of the links was incorrect. It turns out that OpenAI was hallucinating one of the URLs we provided as the citation by combining the first part of the box key with the last part of the comment key. The two keys had a common prefix and OpenAI returned a mangled URL. This resulted in a 404 error since the hallucinated link was invalid.
While the incomplete markdown issue is somewhat annoying, providing the user with incorrect links is unacceptable. So I set out to solve the hallucination issue.
Really short links
What if instead of https://streak.com/a/boxes/{KEY}/itemtype/{KEY} where the keys are lengthy (the URL can be over 200 characters long), the link was simply “#REF3”? Due to the tiny amount of tokens that takes, it’d be significantly less likely that OpenAI would hallucinate by combining unrelated parts of the output due to some shared common prefix. We decided to change the link text to output Wikipedia style numbers, where the links would get output as:
[1](#REF3)
and so on for each reference1. This would work great, and we could simply keep track of which short references map to which original links and replace them on the fly. But where would we perform this substitution? The server streams the output text deltas from OpenAI’s API to the client and each delta is completely arbitrary, where one delta could be “#”, the next delta might be “REF”, with another delta of just “3”. Would we need to provide the client with the complete mapping ahead of time so it could replace the assembled markdown as it’s received? This gets complicated as we may have dozens of citations and the answer may only need to cite one of them.
Bring on the state machine
It turns out there’s an easier, far less complicated solution where we can dynamically detect the start of a markdown link and begin buffering the output on the server, not sending anything to the client until the link has completed. This is simple to do via a state machine. The four states are TEXT, LINK_TEXT, EXIT_LINK_TEXT, and LINK_URL with the following behaviors:
Regardless of state, the
\character acts as an escape character, so we output the next character without any additional consideration.Start out in
TEXTstate, outputting normal text that’s not a link, streaming tokens to the client.Beginning of markdown link via
[character: transition toLINK_TEXTstate and still stream tokens to the client.If in
LINK_TEXTstate and there’s a matching end of markdown link via]character2: transition toEXIT_LINK_TEXTstate and still stream tokens to the client.If in
EXIT_LINK_TEXTstate and next character is(, transition toLINK_URLstate and begin buffering the URL without streaming anything to the client. Otherwise, if the next character is anything else transition back to theTEXTstate and resume streaming.If in
LINK_URLstate and there’s a matching end of the link via)character3, see if the buffered URL exists as a key in our URL map and, if it is, replace the URL with the full URL. Then output the URL to the client and transition back to the defaultTEXTstate.
Since we are asking OpenAI to provide citations using a specific format, this simple processing is sufficient for our needs. The markdown spec is surprisingly robust4, allowing additional formats for links such as:
[link](/uri "title")
[link](</my uri>)
[a](<b)c>)
I haven’t implemented support for the full spec since we have well known formats for our link text and URLs, but should the need arise the state machine can easily be extended. Until then, YAGNI.
Improved output
You can see the result of implementing the above:
No more raw link URLs being flashed to the user. Just nice, clean links that appear as the full URL has been processed. You can see in the event stream that the server streams each output text delta as it’s received from OpenAI, except if there’s a link where the server buffers the link, replaces the short URL with the full URL, and sends the complete link to the client in a single chunk:
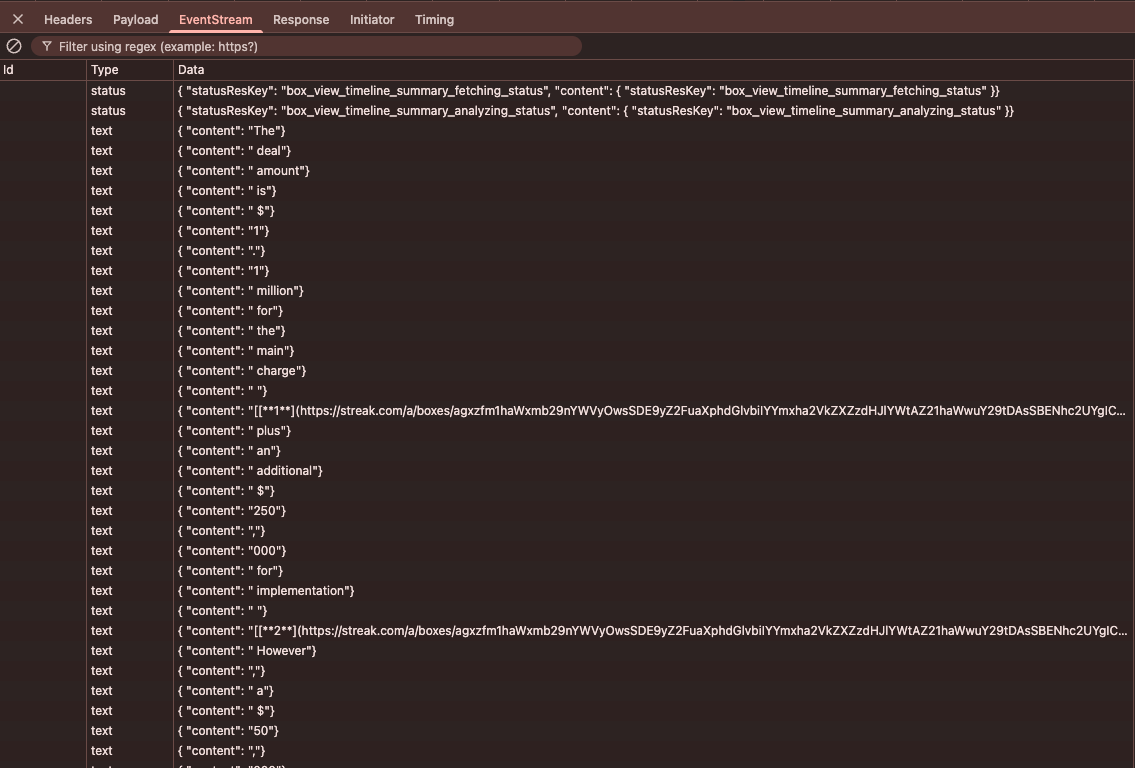
Just plain better
There are multiple benefits from taking this approach:
Instead of sending what ended up being links which consume approximately 50 tokens, our short links are 3 tokens. Fewer tokens means a smaller context for OpenAI and a lower usage bill.
Link hallucinations appear to be a thing of the past, which was the catalyst for making this change.
The streaming response from OpenAI is now much faster since it’s providing the response with our short URLs of only 3 tokens and the speed difference is noticeable to the user.
Since we buffer the URLs server-side and only provide the completed markdown link once we reach the end of the markdown URL, we are preventing flashes of incomplete markdown even if the link isn’t our short reference link. All links benefit from this buffering approach.
While our citation URLs don’t reveal sensitive information and are secured by the user’s Gmail account, there’s an additional privacy bonus in that this substitution never transmits the URL to OpenAI in the first place. For some organizations, this alone could be a win.
Faster, better, and cheaper — can’t go wrong with that!
Engineering at Streak
We work on many interesting challenges affecting millions of users and many terabytes of data. For more information, visit https://www.streak.com/careers
The format of the link reference is completely arbitrary. I had initially wanted to go with just a link URL of “1”, “2”, and so on, but OpenAI started getting confused between the number for the URL and the number it was outputting as the citation text, since not every URL is used. For example, the first citation [1] could be the link URL of “3” or “84”, and OpenAI couldn’t keep the numbers straight.
Additionally, I prefixed the URLs with “#” just in case there is ever a bug in replacing the links since linking a “#REF3” fragment will do nothing, versus a “REF3” link would be interpreted as a relative URL based on the current path, resulting in a 404 error.
Markdown is slightly complicated by the fact that link text can be surrounded by matching brackets. So [example](https://example.com) is a valid regular link, but so is [example [a]](https://example.com), so matching balanced [] characters is important.
Similar to matching [] the link URL can also have matching () characters.
You can see the CommonMark spec at https://spec.commonmark.org/0.31.2/#links